Every hardware company I've worked at has had at least one critically overloaded engineer who didn't show up as overloaded in any system. Not in the project plan. Not in any resource model. Not in the conversation where leadership decided to pull them onto a third initiative.
They were invisible to the system because the system wasn't designed to see them. And by the time someone noticed — usually because something slipped — the damage was already done.
Why This Happens
The most common version of this problem starts with how programs are tracked in isolation. Each program manager owns their spreadsheet. Each spreadsheet has a resource column. The resource column says "Firmware Lead" or a person's name. Nobody is looking across all the spreadsheets at the same time, summing the rows.
So when a new program gets staffed, someone asks informally: "Can we pull [engineer] in for this?" The program manager checks their plan and says yes — because from their view, the engineer has capacity. They're not seeing the three other programs that engineer is already committed to.
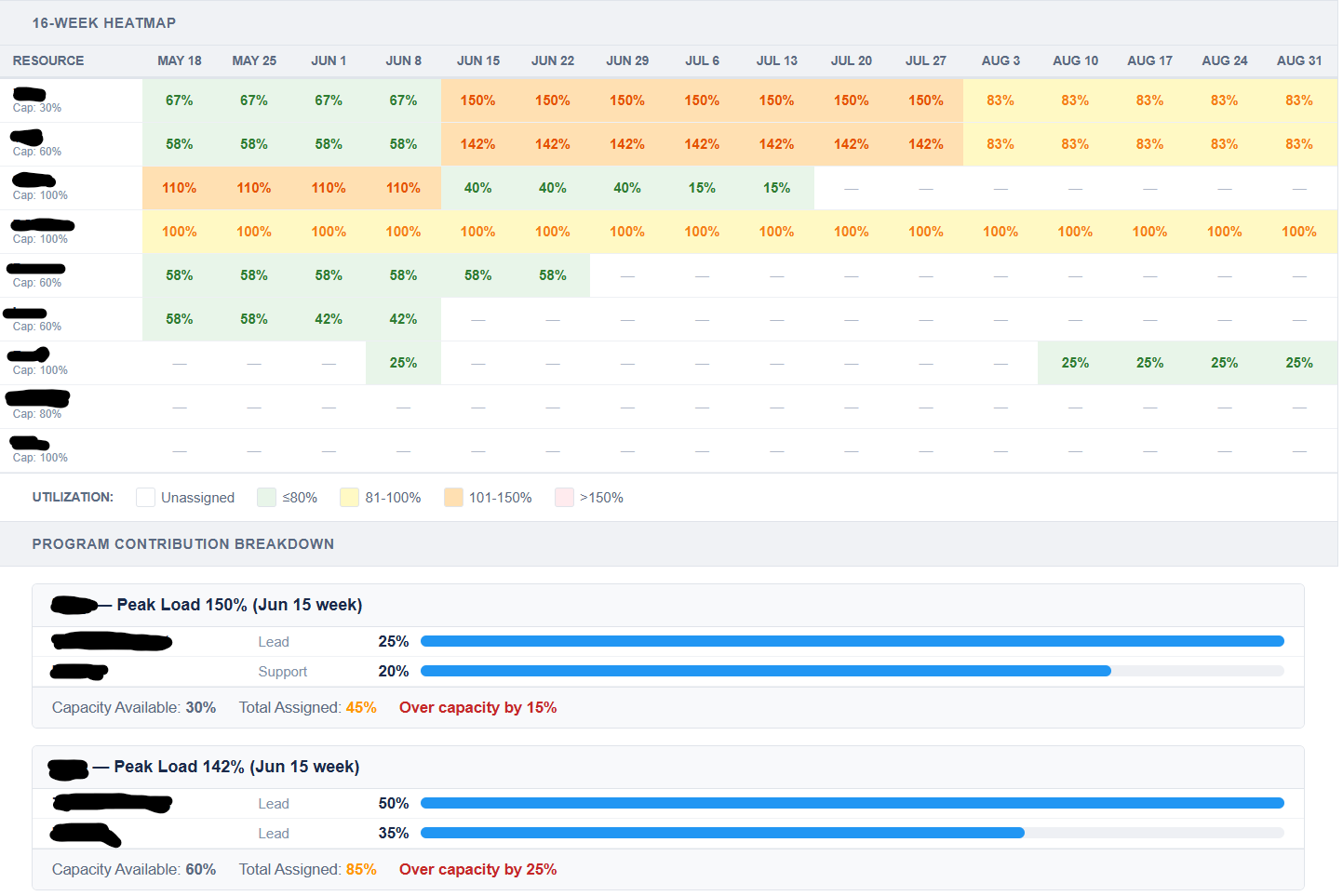
This isn't a communication problem. It's a structural one. The information needed to make a correct staffing decision doesn't exist in any accessible, aggregated form. The correct answer requires a cross-program view. Most companies don't have one.
What the Fix Actually Looks Like
Step One — Commitment Classification
Before you can model resource pressure accurately, you have to distinguish between work that is actually happening and work that is planned, probable, or speculative. If you include speculative programs in your capacity calculations, your model will always show overallocation — and people will stop trusting it. If you exclude them entirely, you lose foresight.
The framework I use runs four states: Committed, Probable, Speculative, On Hold. Only Committed and Probable flow into active capacity modeling. Speculative stays visible but flagged. This one distinction cleans up most of the noise.
Step Two — A Cross-Program Resource Index
Once your programs are classified, you need a single place where resource allocation across all of them is visible simultaneously. Not a meeting. Not a weekly sync. A live view — a table or dashboard — where you can see every engineer, every program they're on, and their aggregate load.
The specific tooling matters less than the discipline. I've built this in Flask with a SQLite backend producing SharePoint-embedded dashboards. I've seen it done adequately in a well-structured spreadsheet. What doesn't work is letting it live in twelve separate spreadsheets and hoping someone remembers to check all of them before making a staffing call.
Step Three — Surface It Before It Matters
The model is only useful if it's consulted at decision time, not after. The point of a resource pressure index isn't to document that someone is overloaded — it's to surface that overallocation is incoming before a commitment is made that locks you in.
That means the model has to be accessible enough that program managers and leadership actually look at it when a staffing question comes up. If it requires IT access, a VPN, or a data export, it won't get used. It needs to live where decisions happen.
The invisible resource problem is one of those things that feels like bad luck when it hits — a delivery miss, a burned-out engineer, a program that slips with no obvious cause. It's almost never bad luck. It's a measurement gap. And measurement gaps are fixable.